大数据开发专家(40K以上)必须掌握技能!
目录:
1.典型需求
2.40K以上专家必备技能
3.项目中的迷宫场景部件制作
4.Hadoop生态核心原理
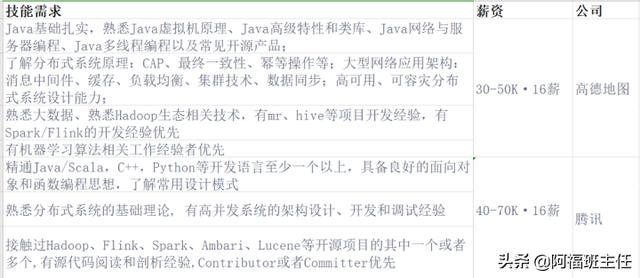
一、典型需求(互联网公司)


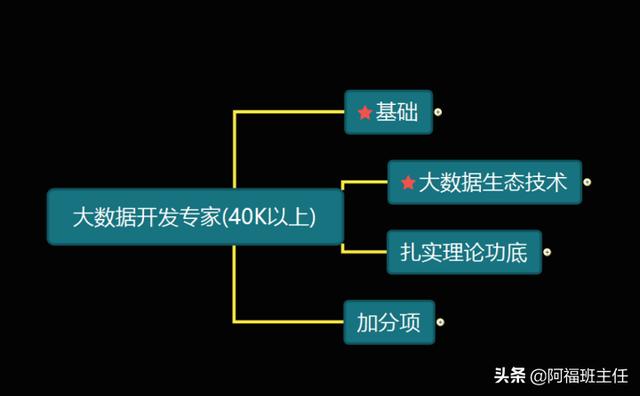
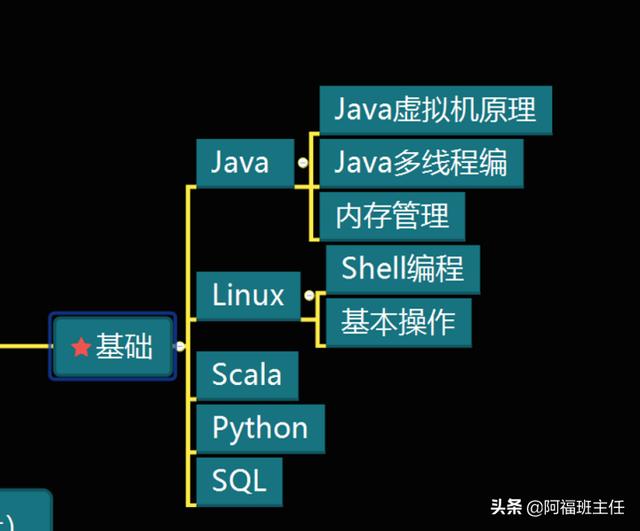
二、40K以上专家必备技能
三、大数从业者角色分类

四、Hadoop生态核心原理
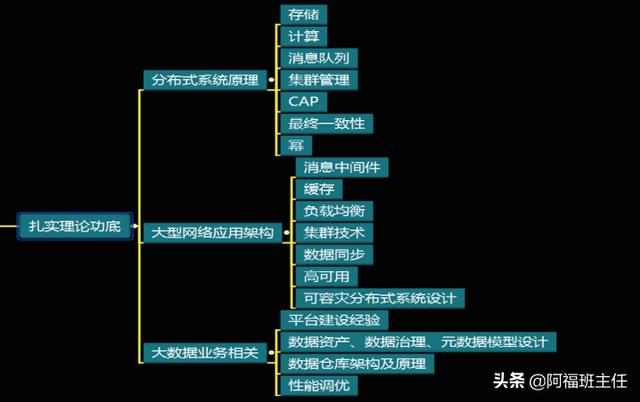
1.大数据整体画像
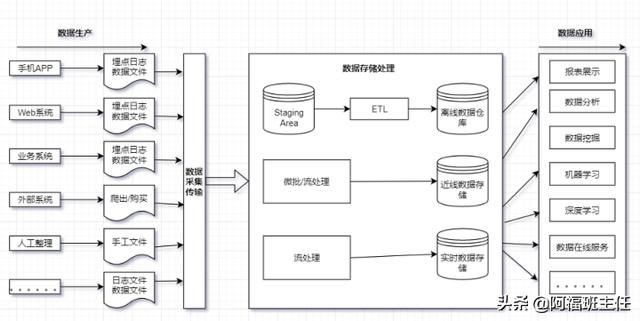
- 数据流程
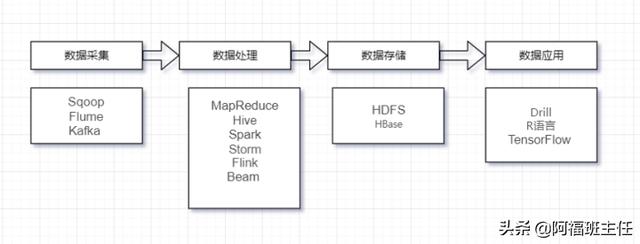
- 数据技术
2.大数据平台整体画像
- 大数据平台逻辑划分
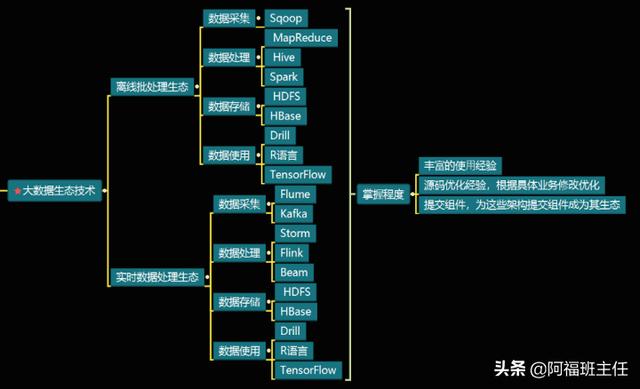
数据相关的工具、产品和技术:比如批量数据采集传输的 Sqoop 、离线数据处理的Hadoop 和Hive 、实时流处理的 Storm和 Spark 以及数据分析的R语言等。
数据资产:不仅包含公司业务本身产生和沉淀的数据,还包括公司运作产生的数据(如财务、行政),以及从外界购买 交换或者爬虫等而来的数据等。
数据管理:有了数据工具,也有了数据资产,但是还必须对它们进行管理才能让数据产生最大价值并最小化风险,因此数据平台通常还包括数据管理的相关概念和技术,如数据仓库、数据建模、 数据质量、数据规范、 数据安全和元数据管理等。在入门大数据的过程中缺乏基础入门视频教程和开发工具,可以戳我领取
- 从数据处理的时效性划分
(1)离线数据平台。
(2)实时数据平台。
- 和离线数据平台相关的技术
Hadoop 、Hive 、数据仓库、 ETL 、维度建模、 数据逻辑分层等。
- 离线数据平台的整体架构

3.Hadoop 核心原理
(1)系统简介
- 正是 Hadoop 开启了大数据时代的大门,而大数据的发展也是和Hadoop 发展密不可的,甚至从某些方面来说大数据就是 Hadoop 。
- Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。
- Hadoop 采用 MapReduce 分布式计算框架,根据 GFS 原理开发了 HDFS(分布式文件系统),并根据 BigTable 原理开发了 HBase 数据存储系统。
- Yahoo、Facebook、Amazon,以及国内的百度、阿里巴巴等众多互联网公司都以 Hadoop 为基础搭建了自己的分布式计算系统。
- Hadoop 是一个基础框架,允许用简单的编程模型在计算机集群上对大型数据集进行分布式处理。
- 用户可以在不了解分布式底层细节的情况下,轻松地在 Hadoop 上开发和运行处理海量数据的应用程序。低成本、高可靠、高扩展、高有效、高容错等特性让 hadoop 成为最流行的大数据分析系统。
(2)Hadoop 生态里的最核心技术
- HDFS:Hadoop 分布式文件系统,它是Hadoop 的核心子项目。
- MapReduce :Hadoop 中的 MapReduce 是一个使用简单的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并能可靠容错地并行处理 TB 级别的数据集。
- Hive :是建立在 Hadoop 体系架构上的一层 SQL抽象,使得数据相关人员使用他们最为熟悉的 SQL 语言就可以进行海量数据的处理、分析和统计工作,而不是必须掌握 Java 等编程语言和具备开发MapReduce 程序的能力。HiveSQL 际上先被 SQL 解析器进行解析然后被 Hive 框架解析成一个MapReduce 可执行计划,并按照该计划生成 MapReduce 任务后交给 Hadoop 集群处理。
(3)HDFS
- 文件系统
文件系统是操作系统提供的磁盘空间管理服务,该服务只需要用户指定文件的存储位置及文件读取路径,而不需要用户了解文件在磁盘上是如何存放的。对于我们编程人员也是这样的。
但是当文件所需空间大于本机磁盘空间时,应该如何处理呢?
加磁盘,但是加到一定程度就有限制了。
加机器,即用远程共享目录的方式提供网络化的存储,这种方式可以理解为分布式文件系统的雏形,它可以把不同文件放入不同的机器中,而且空间不足时可继续加机器,突破了存储空间的限制。
- 传统的分布式文件系统---架构
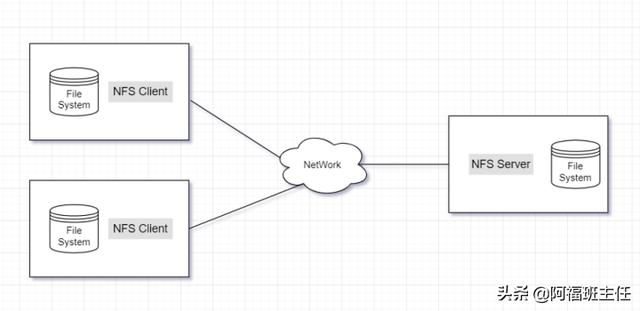
- 传统的分布式文件系统---访问过程
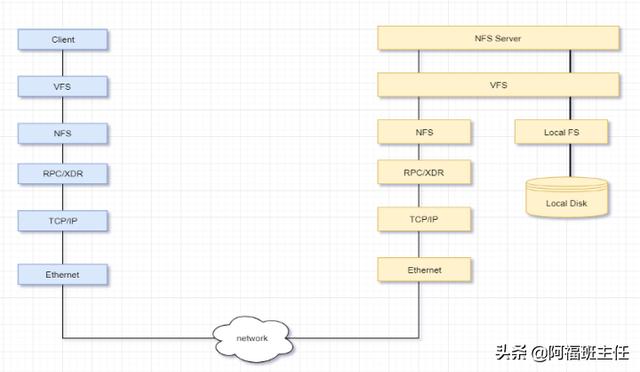
- 传统的分布式文件系统带来的问题
各个存储结点的负载不均衡,单机负载可能极高。例如,如果某个文件是热门文件,则会有很多用户经常读取这个文件,这就会造成该文件所在机器的访问压力极高。
数据可靠性低。如果某个文件所在的机器出现故障,那么这个文件就不能访问了,甚至会造成数据的丢失。
文件管理困难。如果想把一些文件的存储位置进行调整,就需要查看目标机器的空间是否够用,并且需要管理员维护文件位置,在机器非常多的情况下,这种操作就极为复杂。
- HDFS 的基本原理
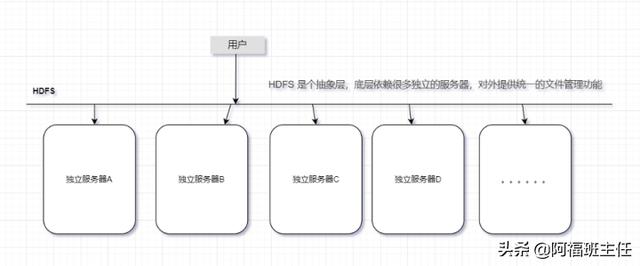
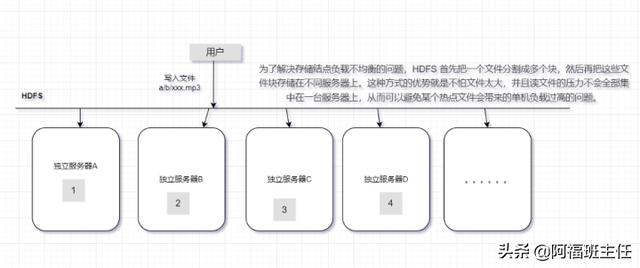
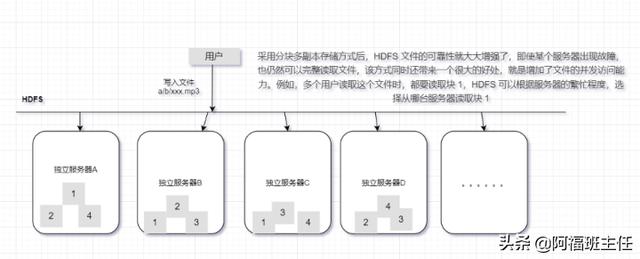
- HDFS 的体系结构(一主多从)
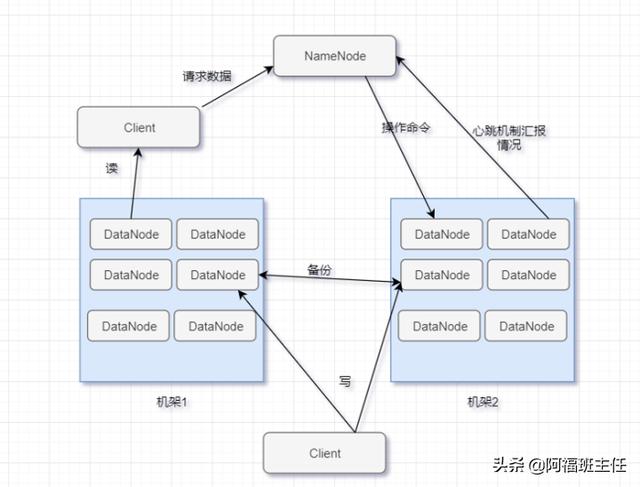
- HDFS 的文件读取

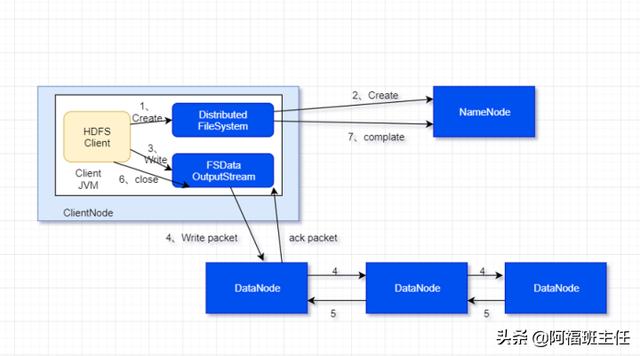
- HDFS 的文件写入
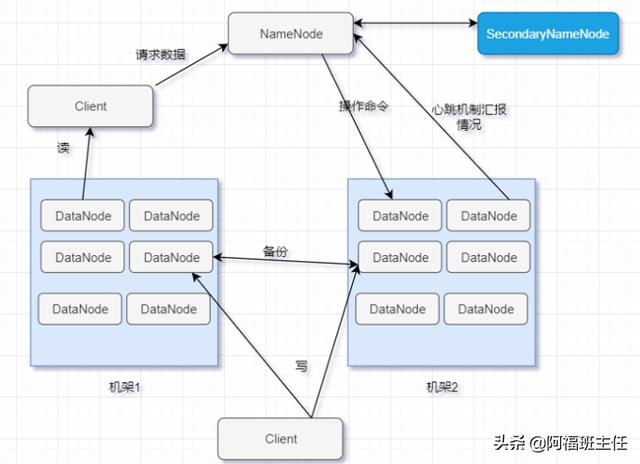
- HDFS 异常处理之NameNode
(1) 两个核心文件
FsImage文件:
a.FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
b.FsImage文件没有记录块存储在哪个数据节点。而是由名称节点把这些映射保留在内存中,这个信息单独在内存中一个区域维护,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名 称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的
EditLog文件:
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
(2)名称节点的启动
在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行 EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读写操作。
接收所有datanodes上的文件块信息汇报,退出安全模式。
(3)名称节点的问题
名称节点运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之,EditLog件将会变得很大,这对名称节点运行没有什么明显影响的,但是,名称节点重启的时候,需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用。
名称节点坏掉了。
(4)解决方案之一
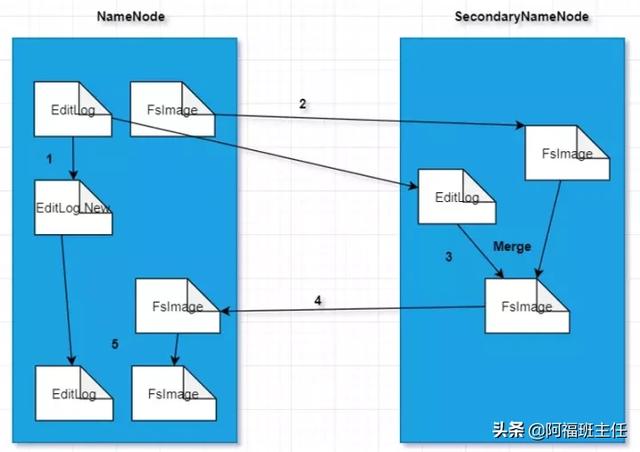
(5)解决方案之二(Hadoop HA)
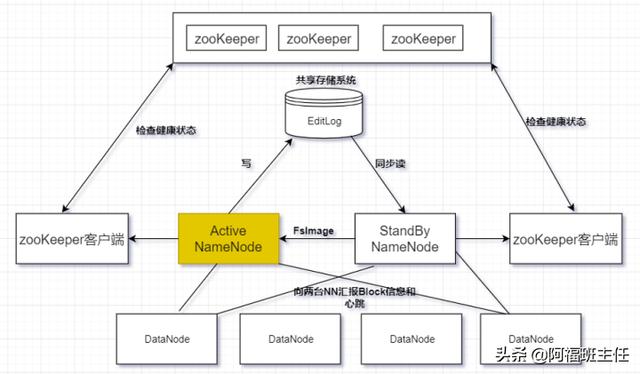
(6)HDFS 异常处理之DataNode
- 数据节点出错
每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态 ,当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都 会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求 这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的 副本数量小于冗余因子 ,名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就 会启动数据冗余复制,为它生成新的副本。HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位。
- 数据出错
客户端在读取到数据后,会采用md5等对数据块进行校验,以确定读取到正确 的数据 ,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块 。
(7)其他
- 优点
a.存储非常大的文件
b.采用流式的数据访问方式
c.运行于普通商用机器
d.高容错、高可靠性
- 不适合的应用场景:
a.低延时的数据访问
b.大量小文件的情况
c.多方读写,需要任意的文件修改
(8)扩展 GFS简介(Google File System)
谈到Hadoop的起源,就不得不提Google的三驾马车:Google FS、MapReduce、BigTable。虽然Google没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文,奠定了风靡全球的大数据算法的基础!
(9)问题
1、为什么不适用于处理大量小文件?
2、HDFS的Block为什么这么大?
3、读取或者写入文件,如果不调用Close方法关闭文件流会咋样?