关于深度学习,这可能是你最容易读进去的科普贴了(七)
编者按:本文作者王川,投资人,中科大少年班校友,现居加州硅谷,个人微信号9935070,微博 @ 硅谷王川。36 氪经授权转载自其个人微信公众号 investguru。查看本系列文章点这里。
一、
神经网络计算,另一个常为人诟病的问题,是过度拟合(overfitting)。
一个拥有大量自由参数的模型,很容易通过调试,和训练数据吻合。但这并不意味着,这就是个好模型。
美国数学家冯纽曼(John Von Neumann)曾说, “给我四个参数,我的模型可以拟合一个大象。给我五个参数, 我可以让它扭动它的鼻子。”

神经网络模型的自由参数,现在往往超过一亿。如果说四个参数可以拟合一个大象的话,对于全世界总数不到一百万的大象来说,实在是游刃有余。
一个模型好坏的试金石,不在于和现有数据的拟合度, 而在于它是否可以在全新的情况和数据面前,做出正确的判断和预测。
金融界的人常会看到各种交易模型,许多模型面对历史数据的测试时,表现非常好,胜率极高。但是如果投资者天真地以为找到了致富的捷径,把模型用于实际交易时,结果往往差强人意。
另外一个典型的过度拟合的例子,可以在小孩教育上看到。许多家长把孩子从小就送到奥数、钢琴、小提琴等各类才艺和竞赛的培训班,唯恐孩子学得不够,以后上不了好大学,找不到好工作。
这实际上就是根据社会现有的经济结构做出的一种过度拟合的训练。
当时代迅速发展,以前吃香的技能,职业突然被淘汰,孩子必须面对社会变化和学校教育体系的巨大落差而无法迅速随机应变时,悲剧将很难避免。
二、
解决这个问题的算法上的革新,启迪又是来自生物界,来自有性繁殖和无性繁殖的对比。
爱尔兰著名哲学家和诗人,奥斯卡*王尔德 (Oscar Wilde)先生曾有名言,"世界上所有东西都是关于性。 除了性本身" (Everything in the world is about sex,Except sex)。

直觉上,有性繁殖是为了生物进化,适应环境。但是如果一个已经非常健康的个体,为什么还要通过有性繁殖,抛弃掉自己一半的优秀基因去和另外一个个体合作制造下一代呢?
无性生殖的优点是节能省时,无须浪费时间求偶交配。但致命的弱点是,基因没有任何变化,遗传病很容易被传播到下一代,进而降低生存的概率。
加州大学伯克利分校学者 Adi Livnat 在2007年的论文, "关于性在进化中的角色的混合能力理论 "(A mixability theory of the role of sex in evolution )中通过模拟计算得出下述结论:
性在生物进化中的目的,不是制造适合某个单一环境的,最优秀的个体基因,而是为了制造最容易和其它多种基因合作的基因,这样在多变的外界环境下,总有一款可以生存延续下来。
优秀个体在有性繁殖中,虽然损失了一半的基因,短期内看上去不是好事。但是长期看,生物组织整体的存活能力,更加稳健强大。
有性繁殖,在金融投资上的一个类比是: 把财富分散到不同种类的资产上,定期重新调整再平衡。 这样做的缺点是,某个表现特别好的资产可能会被过早的卖掉。 但优点在于,让投资组合不过分依赖于某个单一资产,在金融风暴中得以生存下来。
歌舞升平的年代,人们总是互相攀比投资回报、没有觉得生存、保本是个问题。当金融黑天鹅降临时,才幡然醒悟,资本和生命的保全,而不是寻欢作乐,才是真正最重要的。
三、
2012年七月, Hinton 教授发表论文, "通过阻止特征检测器的共同作用来改进神经网络" (Improving neural networks by preventing co-adaptation of feature detectors)。
论文中为了解决过度拟合的问题,采用了一种新的称为"丢弃" (Dropout)的算法。
丢弃算法的具体实施,是在每次培训中,给每个神经元一定的几率(比如 50%),假装它不存在,计算中忽略不计。
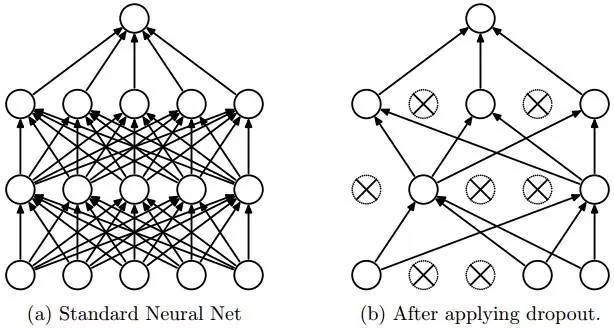
从一个角度看,丢弃算法,每次训练时使用的是不同架构的神经网络(因为每次都有部分神经元装死),最后训练出来的东西,相当于不同架构的神经网络模型的平均值。
从生物的有性繁殖角度看,丢弃算法,试图训练不同的小部分神经元,通过多种可能的交配组合,获得接近理想值的答案。
使用丢弃算法的神经网络,被强迫用不同的、独立的、神经元的子集来接受学习训练。 这样网络更强健,避免了过度拟合的死胡同,不会因为外在输入的很小变化,导致输出质量的很大差异。
论文结果显示,使用丢弃算法后,在诸如 MINST、 TIMID、 CIFAR-10 等多个经典语音和图像识别的问题中, 神经网络在测试数据中的错误率。 相对于经典的深度学习算法,都获得了可观的进步 (错误率下降了 10% 到 30% 不等)。
四、
2012年的夏天, 距离 Hinton 教授 1970年开始攻读博士学位, 距离 Rosenblatt 1971年溺水身亡, 一晃四十多年过去了。
深度学习的技术,此时有了
- GPU快捷的计算速度,
- 海量的训练数据,
- 更多新的聪明的算法。
条件已经成熟, 该用实验结果,证明自己相对别的技术,无可辩驳的优越性了。
有诗为证:
"鸿鹄高飞,一举千里。
羽翼已就,横绝四海。
横绝四海,当可奈何!
虽有缯缴,尚安所施! "
(未完待续)